Enzymes Can’t Tell Artificial DNA From the Real Thing
UC San Diego researchers are exploring how to add letters to the genetic alphabet to make never-before-seen proteins
Published Date
Story by:


Topics covered:
Share This:
Article Content
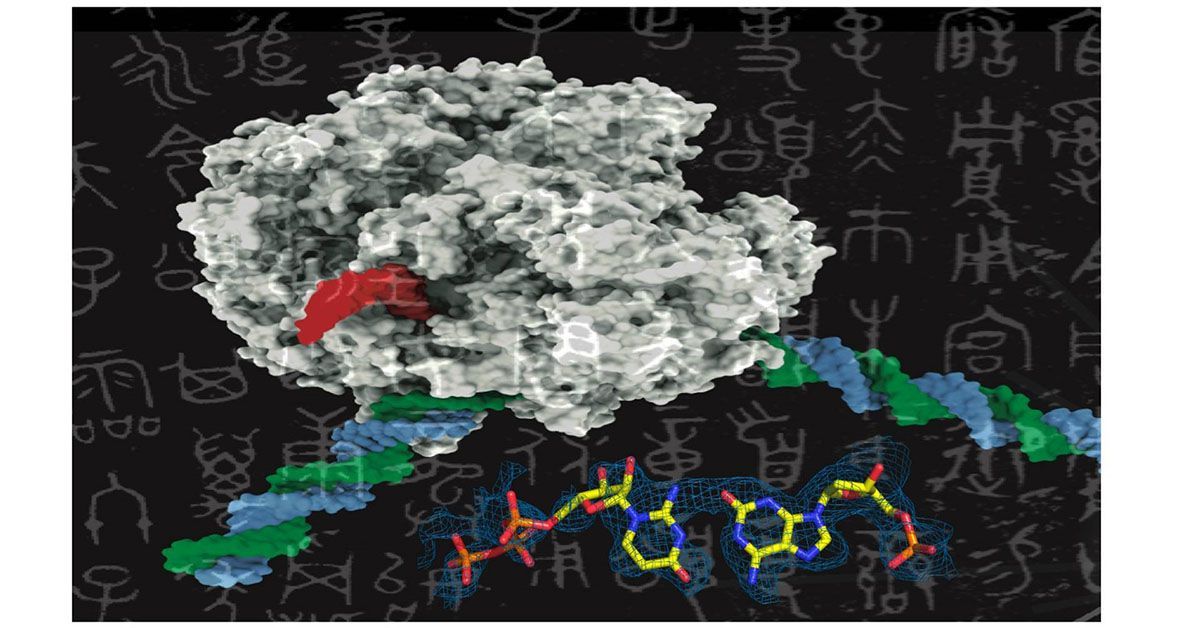
The genetic alphabet contains just four letters, referring to the four nucleotides, the biochemical building blocks that comprise all DNA. Scientists have long wondered whether it’s possible to add more letters to this alphabet by creating brand-new nucleotides in the lab, but the utility of this innovation depends on whether or not cells can actually recognize and use artificial nucleotides to make proteins.
Now, researchers at Skaggs School of Pharmacy and Pharmaceutical Sciences at the University of California San Diego have come one step closer to unlocking the potential of artificial DNA. The researchers found that RNA polymerase, one of the most important enzymes involved in protein synthesis, was able to recognize and transcribe an artificial base pair in exactly the same manner as it does with natural base pairs.
The findings, published December 12, 2023 in Nature Communications, could help scientists create new medicines by designing custom proteins.
“Considering how diverse life on Earth is with just four nucleotides, the possibilities of what could happen if we can add more are enticing,” said senior author Dong Wang, PhD, a professor at Skaggs School of Pharmacy and Pharmaceutical Sciences at UC San Diego. “Expanding the genetic code could greatly diversify the range of molecules we can synthesize in the lab and revolutionize how we approach designer proteins as therapeutics."
Wang co-led the study with Steven A. Benner, PhD, at the Foundation for Applied Molecular Evolution, and Dmitry Lyumkis, PhD, at Salk Institute for Biological Studies.
The four nucleotides that comprise DNA are called adenine (A), thymine (T), guanine (G) and cytosine (C). In a molecule of DNA, nucleotides form base pairs with a unique molecular geometry called Watson and Crick geometry, named for the scientists who discovered the double-helix structure of DNA in 1953. These Watson and Crick pairs always form in the same configurations: A-T and C-G. The double-helix structure of DNA is formed when many Watson and Crick base pairs come together.
“This is a remarkably effective system for encoding biological information, which is why serious mistakes in transcription and translation are relatively rare,” said Wang. “As we’ve also learned, we may be able to exploit this system by using synthetic base pairs that exhibit the same geometry."
The study uses a new version of the standard genetic alphabet, called the Artificially Expanded Genetic Information System (AEGIS), that incorporates two new base pairs. Originally developed by Benner, AEGIS began as a NASA-supported initiative to try to understand how extraterrestrial life could have developed.
By isolating RNA polymerase enzymes from bacteria and testing their interactions with synthetic base pairs, they found that the synthetic base pairs from AEGIS form a geometric structure that resembles the Watson and Crick geometry of natural base pairs. The result: the enzymes that transcribe DNA can’t tell the difference between these synthetic base pairs and those found in nature.
“In biology, structure determines function,” said Wang. “By conforming to a similar structure as standard base pairs, our synthetic base pairs can slip in under the radar and be incorporated in the usual transcription process."
In addition to expanding the possibilities for synthetic biology, the findings also support a hypothesis that dates back to Watson and Crick’s original discovery. This hypothesis, called the tautomer hypothesis, says the standard four nucleotides can form mismatched pairs due to tautomerization, or the tendency of nucleotides to oscillate between several structural variants with the same composition. This phenomenon is thought to be one source of point mutations, or genetic mutations that only impact one base pair in a DNA sequence.
“Tautomerization allows nucleotides to come together in pairs when they aren’t usually supposed to,” said Wang. “Tautomerization of mispairs has been observed in replication and translation processes, but here we provide the first direct structural evidence that tautomerization also happens during transcription.”
The researchers are next interested in testing whether the effect they observed here is consistent in other combinations of synthetic base pairs and cellular enzymes.
“We are excited to assemble a multidisciplinary collaborative team with Steve and Dmitry that allow us to tackle the molecular basis of transcription on expanded alphabet,” said Wang. “There could be many other possibilities for new letters besides what we’ve tested here, but we need to do more work to figure out how far we can take it.”
Co-authors include: Juntaek Oh, Jun Xu and Jenny Chong at UC San Diego, Zelin Shan at the Salk Institute for Biological Sciences and Shuichi Hoshika at Foundation for Applied Molecular Evolution.
This study was funded, in part, by the National Institutes of Health (grants R01661GM102362, R01GM148476, R21CA251043 and U54 AI170855), and the National Science Foundation (grants MCB-2048095 and MCB-2123995).




Stay in the Know
Keep up with all the latest from UC San Diego. Subscribe to the newsletter today.