“Game-powered machine learning” opens door to Google for music
Published Date
Article Content
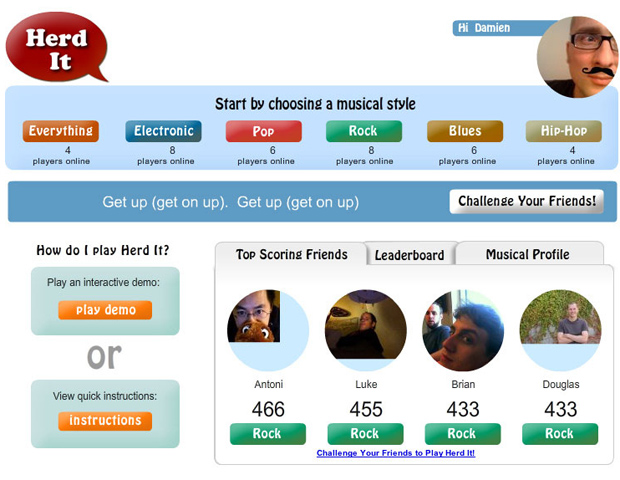
A screen-shot of the Facebook-based game Herd It.
Can a computer be taught to automatically label every song on the Internet using sets of examples provided by unpaid music fans? University of California, San Diego engineers have found that the answer is yes, and the results are as accurate as using paid music experts to provide the examples, saving considerable time and money. In results published in the April 24 issue of the Proceedings of the National Academy of Sciences, the researchers report that their solution, called “game-powered machine learning,” would enable music lovers to search every song on the web well beyond popular hits, with a simple text search using key words like “funky” or “spooky electronica.”
Searching for specific multimedia content, including music, is a challenge because of the need to use text to search images, video and audio. The researchers, led by Gert Lanckriet, a professor of electrical engineering at the UC San Diego Jacobs School of Engineering, hope to create a text-based multimedia search engine that will make it far easier to access the explosion of multimedia content online. That’s because humans working round the clock labeling songs with descriptive text could never keep up with the volume of content being uploaded to the Internet. For example, YouTube users upload 60 hours of video content per minute, according to the company.
In Lanckriet’s solution, computers study the examples of music that have been provided by the music fans and labeled in categories such as “romantic,” “jazz,” “saxophone,” or “happy.” The computer then analyzes waveforms of recorded songs in these categories looking for acoustic patterns common to each. It can then automatically label millions of songs by recognizing these patterns. Training computers in this way is referred to as machine learning. “Game-powered” refers to the millions of people who are already online that Lanckriet’s team is enticing to provide the sets of examples by labeling music through a Facebook-based online game called Herd It.
“This is a very promising mechanism to address large-scale music search in the future,” said Lanckriet, whose research earned him a spot on MIT Technology Review’s list of the world’s top young innovators in 2011.
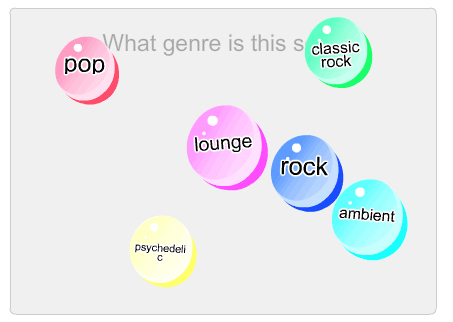
Screen-shot of the Facebook game Herd It. The game acts as an incentive for online music fans to classify music, providing sets of examples that are used to train computers to automatically label more songs.
Another significant finding in the paper is that the machine can use what it has learned to design new games that elicit the most effective training data from the humans in the loop. “The question is if you have only extracted a little bit of knowledge from people and you only have a rudimentary machine learning system, can the computer use that rudimentary version to determine the most effective next questions to ask the people?” said Lanckriet. “It’s like a baby. You teach it a little bit and the baby comes back and asks more questions.” For example, the machine may be great at recognizing the music patterns in rock music but struggle with jazz. In that case, it might ask for more examples of jazz music to study.
It’s the active feedback loop that combines human knowledge about music and the scalability of automated music tagging through machine learning that makes “Google for music” a real possibility. Although human knowledge about music is essential to the process, Lanckriet’s solution requires relatively little human effort to achieve great gains. Through the active feedback loop, the computer automatically creates new Herd It games to collect the specific human input it needs to most effectively improve the auto-tagging algorithms, said Lanckriet. The game goes well beyond the two primary methods of categorizing music used today: paying experts in music theory to analyze songs – the method used by Internet radio sites like Pandora – and collaborative filtering, which online book and music sellers now use to recommend products by comparing a buyer’s past purchases with those of people who made similar choices.
Both methods are effective up to a point. But paid music experts are expensive and can’t possibly keep up with the vast expanse of music available online. Pandora has just 900,000 songs in its catalog after 12 years in operation. Meanwhile, collaborative filtering only really works with books and music that are already popular and selling well.
The big picture: Personalized radio
Lanckriet foresees a time when – thanks to this massive database of cataloged music -- cell phone sensors will track the activities and moods of individual cell phone users and use that data to provide a personalized radio service – the kind that matches music to one’s activity and mood, without repeating the same songs over and over again.
“What I would like long-term is just one single radio station that starts in the morning and it adapts to you throughout the day. By that I mean the user doesn’t have to tell the system, “Hey, it’s afternoon now, I prefer to listen to hip hop in the afternoon. The system knows because it has learned the cell phone user’s preferences.”
This kind of personalized cell phone radio can only be made possible if the cell phone has a large database of accurately labeled songs from which to choose. That’s where efforts to develop a music search engine are ultimately heading. The first step is figuring out how to label all the music online well beyond the most popular hits. As Lanckriet’s team demonstrated in PNAS, game-powered machine learning is making that a real possibility.
Lanckriet’s research is funded by the National Science Foundation, National Institutes of Health, the Alfred P. Sloan Foundation, Google, Yahoo!, Qualcomm, IBM and eHarmony.
Share This:
You May Also Like




Stay in the Know
Keep up with all the latest from UC San Diego. Subscribe to the newsletter today.