Fighting AI Fire with ML Firepower
UC San Diego computer scientists prevent malicious and fabricated AI-generated content with a new framework for data redaction

Published Date
Story by:
Media contact:


Share This:
Article Content
Fake robocalls during elections. The voice of a public figure appropriated to hawk products. Pictures altered to mislead the public. From social media posts to celebrity voices, the trustworthiness of AI-generated content is under fire. So here’s the burning question: how do we stamp out harmful or undesirable content without dampening innovation?
Computer scientists from the University of California San Diego Jacobs School of Engineering have proposed a novel solution to optimize the tremendous potential of deep generative models while mitigating the production of content that is biased or toxic in nature.
In a 2024 IEEE Secure and Trustworthy Machine Learning paper, Data Redaction from Conditional Generative Models, researchers introduced a framework that would prevent text-to-image and speech synthesis models from producing undesirable outputs. Their innovative approach earned a Distinguished Paper Award at the IEEE conference held recently at the University of Toronto.
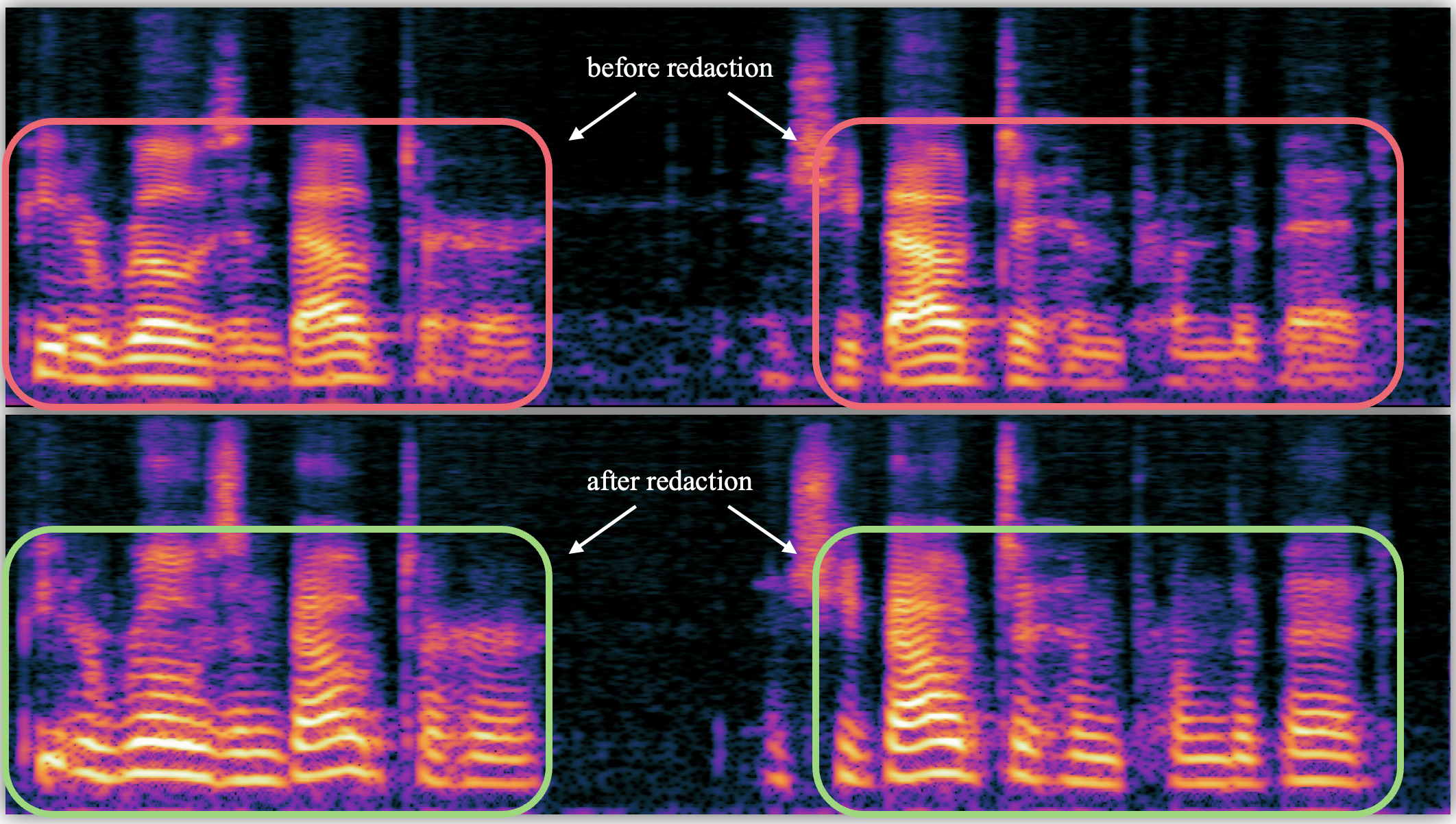
First row shows speech of a specific voice generated by a pretrained model. Second row shows the speech of the same transcriptions after applying the researcher's method to redact the concept of the voice presented in the first sample-- demonstrating that their method knows clearly to redact voices while retaining speech quality and transcriptions. (Listen to sound samples here.)

Zhifeng Kong, a UC San Diego computer science PhD graduate, is the first author on the story.
“Modern deep generative models often produce undesirable outputs – such as offensive texts, malicious images, or fabricated speech – and there is no reliable way to control them. This paper is about how to prevent this from happening technically,” said Zhifeng Kong, a UC San Diego Computer Science and Engineering Department PhD graduate and lead author of the paper.
“The main contribution of this work is to formalize how to think about this problem and how to frame it properly so that it can be solved,” said UC San Diego computer science Professor Kamalika Chaudhuri.
A new method to extinguish harmful content
Traditional mitigation methods have taken one of two approaches. The first method is to re-train the model from scratch using a training set that excludes all undesirable samples; the alternative is to apply a classifier that filters undesirable outputs or edits outputs after the content has been generated.
These solutions have certain limitations for most modern, large models. Besides being cost-prohibitive—requiring millions of dollars to retrain industry scale models from scratch— these mitigation methods are computationally heavy, and there’s no way to control whether third parties will implement available filters or editing tools once they obtain the source code. Additionally, they might not even solve the problem: sometimes undesirable outputs, such as images with artifacts, appear even though they are not present in the training data.
Chaudhuri and Kong aim to mitigate undesired content while overcoming each of these hurdles. They were inspired to design a formal statistical machine learning framework that was effective, universal, and computationally efficient while retaining high-generation quality.
Specifically, the team proposed to post-edit the weights of a pre-trained model, a method they call data redaction. They introduced a series of techniques to redact certain conditionals, or user inputs, that will, with high statistical probability, lead to undesirable content.

Computer science professor Kamalika Chaudhuri
Prior work in data redaction focused on unconditional generative models. Those studies considered the problem in the space of outputs, redacting generated samples. That same technique is too unwieldy to apply to conditional generative models, which typically learn an infinite number of distributions.
Chaudhuri and Kong overcame this challenge by redacting in the conditional space rather than the output space. With text-to-image models they redacted prompts; in text-to-speech models, they redacted voices. In short, they extinguished sparks before they could be fanned into toxic output.
For example, in the text-to-speech context, they could redact a specific person’s voice, such as a celebrity voice. The model would then generate a generic voice in place of the celebrity voice, making it much more difficult to put words in someone’s mouth.
The team’s method — which only needed to load a small fraction of the dataset — kept their data redaction computationally light. It also offered better redaction quality and robustness than baseline methods and retained similar generation quality as the pre-trained model.
The researchers note that this work is a small-scale study which provides an approach that is applicable to most types of generative models.
“If this was to be scaled up and applied to much bigger and modern models, then the ultimate broader impact would be a path towards safer generative models,” said Chaudhuri.
This work was supported by the National Science Foundation (1804829) and an Army Research Office MURI award (W911NF2110317).
Learn more about research and education at UC San Diego in: Artificial Intelligence
Share This:
You May Also Like




Stay in the Know
Keep up with all the latest from UC San Diego. Subscribe to the newsletter today.